Wafer-level large chips, proposed by the Chinese Academy of Sciences
tech
The true Moore's Law, that is, transistors becoming cheaper and faster with each process shrink, is what's driving chip manufacturers crazy. There are two different methods to manufacture computing engines with greater capacity but typically not faster, which are breaking down devices into smaller chips and connecting them together or etching them across an entire silicon wafer, plus a third overlay, both of which can be used in conjunction with 2.5D and 3D stacking to expand capacity and functionality.
Regardless, all these methods are limited by the mask set of the photolithography equipment used to etch the chips. Current equipment is customized for 300 mm silicon wafers, with a barrier of 858 mm^2, and that's it. No chip can be etched larger than this. Over the past thirty years, the transition from 150 mm wafers to 200 mm wafers to 300 mm wafers has not changed the mask set limit, and neither has the evolution from visible light lithography to immersion lithography to extreme ultraviolet lithography. It is assumed that moving to 450 mm wafers will not change the mask set limitation. By 2023, having 450 mm wafers will allow for larger capacity wafer-level computing engines. However, the engineering challenges of 450 mm wafers are too difficult for IBM, Intel, Samsung, TSMC, GlobalFoundries, and Nikon to solve, and this effort was abandoned in 2015.
Advertisement
The mask limitation (the aperture size through which light passes through the chip mask to etch transistor holes on the silicon wafer) not only defines the design of small chips but also restricts the size of discrete computing and memory blocks on a single wafer. It would be amazing if we had 450 mm wafers and all the logic of wafer-level computers could be etched at once with a mask set larger than the wafer, but that's not how photolithography equipment works. In summary, the difference between small chips and wafer-level is actually in how interconnections are built to leverage discrete elements of computing and memory to construct computing engine slots.
Despite such limitations, the industry always needs to build more powerful computing engines, and at the end of Moore's Law, it would be great if a method could be found to also make these devices cheaper to manufacture.
Researchers at the Institute of Computing Technology of the Chinese Academy of Sciences (CAS) have just published a paper in the journal "Basic Research," discussing the limitations of lithography and small chips, and proposing an architecture they call the "large chip," which emulates the wafer-level Trilogy Systems efforts in the 1980s and the successful wafer-level architecture of Cerebras Systems in the 2020s. Elon Musk's Tesla is building its own "Dojo" supercomputer chip, but this is not a wafer-level design; instead, it is a complex packaging of Dojo D1 cores into something that, if you squint, looks like a wafer-level slot built from 360 small chips. Perhaps with the Dojo2 chip, Tesla will move towards a true wafer-level design. It seems that not much work is needed to accomplish such a feat.
The paper compiled by CAS discusses many issues about why it is necessary to develop wafer-level devices but does not provide many details about what their developed large chip architecture actually looks like. It does not indicate whether the large chip will adopt the small chip approach like Tesla's Dojo or develop towards wafer-level like Cerebras has done from the start.
The researchers indicate that the design can scale to 100 small chips in a single discrete device, which we used to call slots but sounds more like system boards to us. It is currently unclear how these 100 small chips will be configured, nor is it clear what kind of memory architecture these small chips will implement (there will be 1,600 cores in the array).
What we do know is that with the iteration of the large chip, there are 16 RISC-V processors using an on-chip network for symmetric multiprocessing on shared main memory, interconnected, and with SMP links between small chips, so each block can share memory across the entire composite.
CAS researchers say that there is absolutely nothing to prevent this small chip design from being implemented at the wafer level. However, for this iteration, it appears that it will be small chips interconnected using a 2.5D interposer.Interconnects are as crucial as computational components, a fact that has always held true in the design of systems and subsystems.
"The interface is designed using a channel sharing technology based on time-multiplexing mechanisms," the researchers wrote when discussing D2D interconnects. "This approach reduces the number of signals between chips, thereby minimizing the area overhead of I/O bumps and interposer wiring resources, which can significantly reduce the complexity of substrate design. The small chip terminates at the top metal layer, with micro I/O pads built directly on that metal layer."
While a large chip computing engine as a multi-chip or wafer-level composite may be intriguing, it is important to consider how these devices are interconnected to provide exascale computing systems. Here is what CAS researchers have to say on this matter:
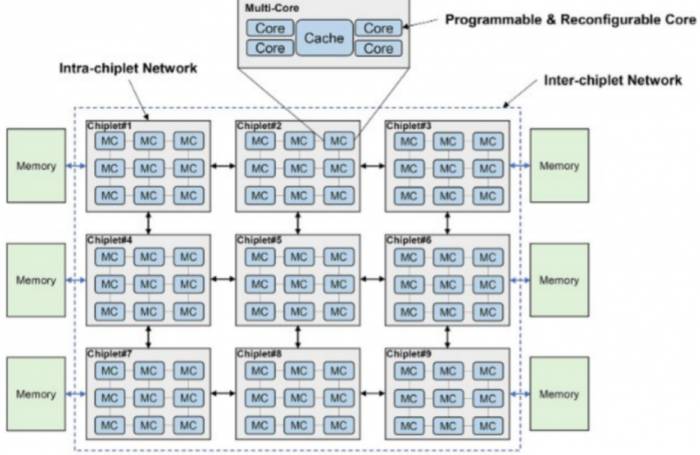
The researchers wrote, "For current and future exascale computing, we predict that a tiered chiplet architecture will be a powerful and flexible solution," as shown in the figure below, which is a lengthy excerpt from the CAS paper. "The tiered chiplet architecture is designed with multiple cores and many chiplets with tiered interconnects. Within the chiplet, cores communicate using ultra-low latency interconnects, while chiplets communicate with each other via low-latency interconnects that benefit from advanced packaging technologies, thus minimizing on-chip latency and NUMA effects in this highly scalable system. The memory hierarchy includes core memory, on-chip memory, and off-chip memory. These three levels of memory differ in terms of memory bandwidth, latency, power consumption, and cost. In the overview of the tiered chiplet architecture, multiple cores are connected through a crossbar switch and share caches. This forms a pod structure, and pods are interconnected via the chiplet's internal network. Multiple pods form a chiplet, which is interconnected via a chiplet-to-chiplet network and then connected to off-chip memory. Careful design is required to fully leverage this hierarchy. Proper utilization of memory bandwidth to balance workloads across different computational tiers can significantly improve the efficiency of chiplet systems. Correctly designing communication network resources ensures that chiplets collaborate on shared memory tasks."
It is difficult to argue with anything stated in this passage, but the CAS researchers do not specify how they will actually address these issues. This is the most challenging part.
Interestingly, the cores in the diagram are referred to as "programmable" and "reconfigurable," but it is unclear what this entails. It may require the use of variable threading technologies (such as IBM's Power8, Power9, and Power10 processors) to accomplish more work rather than mixing CPU and FPGA components within the cores.
CAS researchers indicate that the large chip computing engine will consist of over one trillion transistors, occupying a total area of thousands of square millimeters, using chiplet packaging or wafer-level integration of computing and storage blocks. For exascale HPC and AI workloads, we believe CAS is likely considering HBM stacked DRAM or some alternative to dual-pumped main memory, such as the MCR memory developed by Intel and SK Hynix. RISC-V cores may have a substantial amount of local SRAM for computation, which could eliminate the need for HBM memory and allow for the acceleration of DDR5 memory using MCR dual-pumped technology. Much depends on the workload and their sensitivity to memory capacity and memory bandwidth.